반응형
웹 서비스 자원들이 어느 경로에 위치 하였는지 스캔 하고,
그 결과를 디스플레이 해주는 단순한 도구 dirsearch.
도구 이름 그대로 search에 집중해주기 때문에
적절한 옵션 사용이 대상을 스캔할 때 도움이 된다.

또한 이 도구는 웹 서버에서 디렉토리와 파일을 무차별 대입(brute force)하는 명령줄 도구가 포함되어 있으므로,
적합한 사용이 필요함은 물론이다.
◎ dirsearch의 주요 옵션
| Usage: dirsearch.py [-u|--url] target [-e|--extensions] extensions [options] Options: --version show program's version number and exit -h, --help show this help message and exit Mandatory: -u URL, --url=URL Target URL(s), can use multiple flags -l PATH, --url-file=PATH URL list file --stdin Read URL(s) from STDIN --cidr=CIDR Target CIDR --raw=PATH Load raw HTTP request from file (use '--scheme' flag to set the scheme) -s SESSION_FILE, --session=SESSION_FILE Session file --config=PATH Path to configuration file (Default: 'DIRSEARCH_CONFIG' environment variable, otherwise 'config.ini') Dictionary Settings: -w WORDLISTS, --wordlists=WORDLISTS Customize wordlists (separated by commas) -e EXTENSIONS, --extensions=EXTENSIONS Extension list separated by commas (e.g. php,asp) -f, --force-extensions Add extensions to the end of every wordlist entry. By default dirsearch only replaces the %EXT% keyword with extensions -O, --overwrite-extensions Overwrite other extensions in the wordlist with your extensions (selected via `-e`) --exclude-extensions=EXTENSIONS Exclude extension list separated by commas (e.g. asp,jsp) --remove-extensions Remove extensions in all paths (e.g. admin.php -> admin) --prefixes=PREFIXES Add custom prefixes to all wordlist entries (separated by commas) --suffixes=SUFFIXES Add custom suffixes to all wordlist entries, ignore directories (separated by commas) -U, --uppercase Uppercase wordlist -L, --lowercase Lowercase wordlist -C, --capital Capital wordlist General Settings: -t THREADS, --threads=THREADS Number of threads -r, --recursive Brute-force recursively --deep-recursive Perform recursive scan on every directory depth (e.g. api/users -> api/) --force-recursive Do recursive brute-force for every found path, not only directories -R DEPTH, --max-recursion-depth=DEPTH Maximum recursion depth --recursion-status=CODES Valid status codes to perform recursive scan, support ranges (separated by commas) --subdirs=SUBDIRS Scan sub-directories of the given URL[s] (separated by commas) --exclude-subdirs=SUBDIRS Exclude the following subdirectories during recursive scan (separated by commas) -i CODES, --include-status=CODES Include status codes, separated by commas, support ranges (e.g. 200,300-399) -x CODES, --exclude-status=CODES Exclude status codes, separated by commas, support ranges (e.g. 301,500-599) --exclude-sizes=SIZES Exclude responses by sizes, separated by commas (e.g. 0B,4KB) --exclude-text=TEXTS Exclude responses by text, can use multiple flags --exclude-regex=REGEX Exclude responses by regular expression --exclude-redirect=STRING Exclude responses if this regex (or text) matches redirect URL (e.g. '/index.html') --exclude-response=PATH Exclude responses similar to response of this page, path as input (e.g. 404.html) --skip-on-status=CODES Skip target whenever hit one of these status codes, separated by commas, support ranges --min-response-size=LENGTH Minimum response length --max-response-size=LENGTH Maximum response length --max-time=SECONDS Maximum runtime for the scan --exit-on-error Exit whenever an error occurs Request Settings: -m METHOD, --http-method=METHOD HTTP method (default: GET) -d DATA, --data=DATA HTTP request data --data-file=PATH File contains HTTP request data -H HEADERS, --header=HEADERS HTTP request header, can use multiple flags --header-file=PATH File contains HTTP request headers -F, --follow-redirects Follow HTTP redirects --random-agent Choose a random User-Agent for each request --auth=CREDENTIAL Authentication credential (e.g. user:password or bearer token) --auth-type=TYPE Authentication type (basic, digest, bearer, ntlm, jwt, oauth2) --cert-file=PATH File contains client-side certificate --key-file=PATH File contains client-side certificate private key (unencrypted) --user-agent=USER_AGENT --cookie=COOKIE Connection Settings: --timeout=TIMEOUT Connection timeout --delay=DELAY Delay between requests --proxy=PROXY Proxy URL (HTTP/SOCKS), can use multiple flags --proxy-file=PATH File contains proxy servers --proxy-auth=CREDENTIAL Proxy authentication credential --replay-proxy=PROXY Proxy to replay with found paths --tor Use Tor network as proxy --scheme=SCHEME Scheme for raw request or if there is no scheme in the URL (Default: auto-detect) --max-rate=RATE Max requests per second --retries=RETRIES Number of retries for failed requests --ip=IP Server IP address Advanced Settings: --crawl Crawl for new paths in responses View Settings: --full-url Full URLs in the output (enabled automatically in quiet mode) --redirects-history Show redirects history --no-color No colored output -q, --quiet-mode Quiet mode Output Settings: -o PATH, --output=PATH Output file --format=FORMAT Report format (Available: simple, plain, json, xml, md, csv, html, sqlite) --log=PATH Log file |
반응형
하나 예를 해보는데,
옵션 -u 다음에 스캔 대상 url 주소를,
그리고 403, 401 에러가 발생하는 페이지는 검색에서 제외를 한다는 옵션을 주고 도구를 실행한다.
그러면 도구는 시작에 앞서 몇 가지 정보를 보여주는데,

Extensions : 명시된 확장자에 대해 모두 검색을 한다.
HTTP Method : GET 으로 자원 요청을 하고,
Threads : 30은 말 그대로 30개 threads 사용
Wordlist size : 도구에서 갖고 있는 워드리스트에 명시된 자원 이름에 따라 검색을 진행하는데, 이 리스트에 포함된 size가 10927로 10,927개의 잘 알려진 자원 목록이 있다고 봐도 되겠다.
이에 대한 결과의 일부.
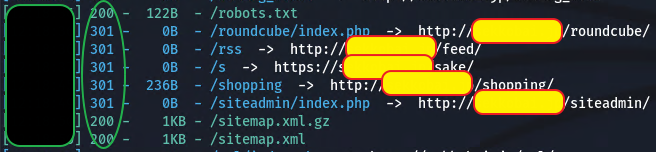
도구는 http 200과 301로 응답받은 자원 호출 결과에 대해 리스트로 보여준다.
200으로 받은 결과는 해당 웹 서버 경로에 존재하고,
301로 받은 결과는 다른 경로에서 확인을 해봐야 함을 알 수 있다.
오늘도 단순한 도구 사용, dirsearch였다.
반응형
'===취미 세상 : 공부=== > 칼리리눅스' 카테고리의 다른 글
| parsero - 웹서비스 disallow 항목 검색 도구 (18) | 2023.03.29 |
|---|---|
| sslscan - 암호화 통신 여부 확인 도구 (33) | 2023.03.28 |
| whatweb - 웹사이트 서비스 정보 수집 도구 (28) | 2023.03.17 |
| wpscan - wordpress 워드프레스 취약점 정보 수집 도구 (41) | 2023.03.03 |
| joomscan - joomla 줌라 취약점 정보 수집 도구 (18) | 2023.03.02 |